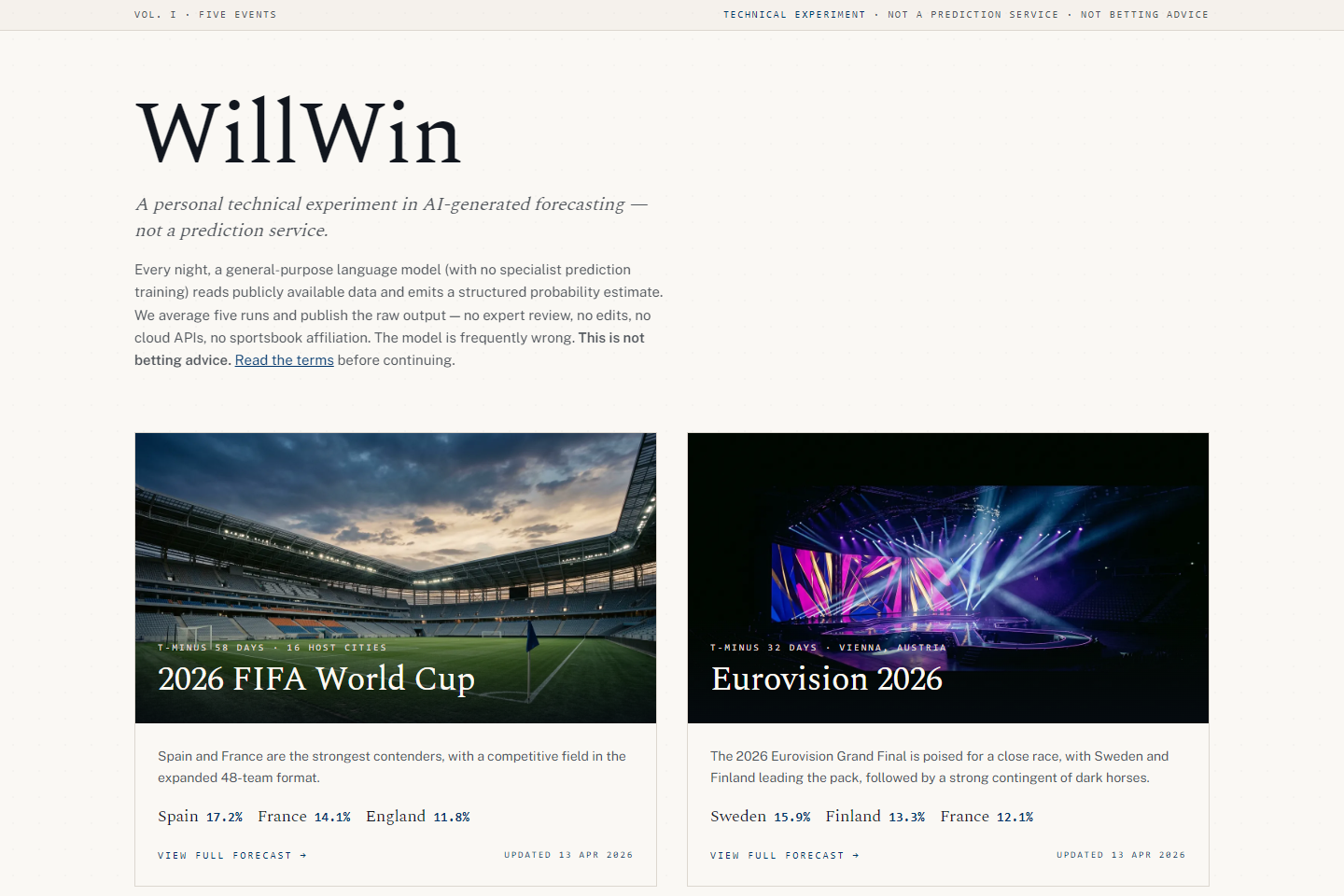
Disclaimer. WillWin is a personal technical experiment in AI engineering — not a prediction service, not betting advice, not financial advice, and not affiliated with FIFA, UEFA, the EBU, Formula 1, the ASO, the Academy of Motion Picture Arts and Sciences, or any event organiser, team, artist, or broadcaster. Outputs are machine-generated from publicly available text and are frequently wrong. Nothing on the site or in this article should be used to place wagers or make any decision with financial, legal, or personal consequences. All brand names belong to their respective owners and are used purely for reference.
I've been wanting an excuse to stress-test a single language model against the kind of predictions that usually require a team of analysts, a stack of proprietary data, and a few hundred thousand dollars of infrastructure. So I built WillWin — a forecast engine that runs every night on a local RTX 5090, reads public data sources, asks a 32B open-weights model to reason through them five times, averages the answers, and publishes the result as a static site.
It's a pure engineering exercise — how far can one open-source model, a stack of public text, and a single consumer GPU get at a problem that normally demands proprietary data and a quant team? The outputs cover the 2026 FIFA World Cup, Eurovision, the F1 Drivers' Championship, the Tour de France GC, and the Oscars' Best Picture race. The outputs are published for transparency and as a teaching artefact. They are not a product, a service, or a recommendation.
The premise: an experiment, not a product
Most consumer-facing AI prediction sites fall into one of two failure modes. Either they're thin vibes-based content ("our AI thinks Brazil will win!") with no visible pipeline, or they're locked behind "smart betting" paywalls with opaque models. WillWin is not either of those. It is deliberately the opposite: a site that shows every source, every transformation, and tells you up-front, on every page, that the model will be wrong, probably often.
The brand voice is the tell. Every page carries a TECHNICAL EXPERIMENT — NOT A PREDICTION SERVICE — NOT BETTING ADVICE strap. The bylines read like an academic journal: "Vol. 1 — No. 68 / 13 Apr 2026, 06:30 / live estimate — updated 13 Apr 2026, data completeness 66% (not a measure of accuracy)." The last parenthetical matters more than any headline probability.
Nothing is sold on the site. There are no affiliate links, no betting partners, no sponsored picks, no "premium tier." There is no newsletter trying to monetise the forecasts. There never will be.
What it looks like
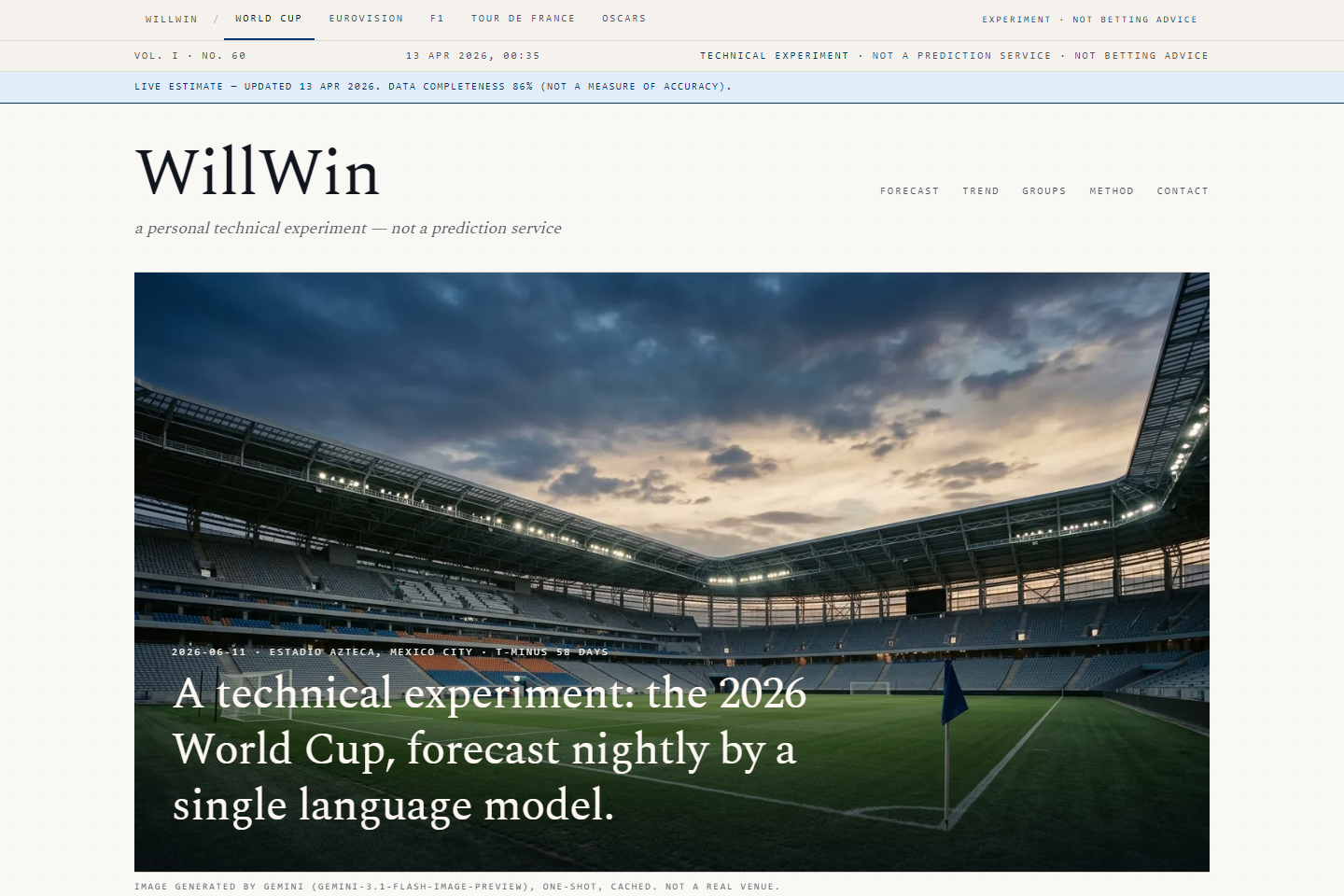
Each event has its own page with the same layout: a hero framing the story in plain English, a live-updating top-picks table with per-contender probabilities, dark-horse picks, an interactive chart of how the forecast has moved over time, and a few editorial touches (ambient stadium audio, cinematic hero imagery) that make clear this is a creative technical project rather than a data service.
Pressing the D key on any event page opens a data-history overlay showing the last 20 snapshots side-by-side with per-source counts, so you can watch yesterday's favourite get downgraded by today's news cycle. This is deliberate: the site's most interesting output isn't the headline pick, it's watching the model change its mind in public.
Under the hood

The nightly pipeline is the whole point of the project. A cron job on the VPS wakes up, stages five scripts across an hour (04:30–06:30 UTC, one per event), each of which:
- Fetches the public record. All inputs are public, freely available, and respect each source's terms. For the World Cup that's Elo ratings from eloratings.net, group-stage metadata from the open-source openfootball project on GitHub, a static frozen reference snapshot (live scraping is disabled for ToS compliance), hand-curated squad metadata, recent results from football-data.org's free tier, Wikipedia REST-API summaries, and Brave Search's web + news endpoints. The other four events use a leaner four-source mix: Brave Web, Brave News, Wikipedia, and a contest metadata file.
- Builds a structured prompt. Each source gets its own labelled block. Elo ratings become a ranked table. Recent form is compressed into a W/D/L string per team. News items are deduped by URL and capped. Nothing is summarised by an LLM on the way in — the source data is raw.
- Runs the model five times. The prompt is piped over an SSH tunnel to a local RTX 5090 running the open-weights
qwen3:32bvia Ollama, five independent generations at temperature 0.7. Each run takes roughly 90 seconds; a full event cycle is about 7–8 minutes. - Averages and renormalises. Top-N picks are averaged across runs, then renormalised. Confidence is a closed-form function of how many sources returned data and how many runs completed, and it is hard-capped at 0.92 — the site never claims greater certainty than that, regardless of how sure the model sounds.
- Commits, deploys. The cron writes
current.jsonand appends tohistory.json, commits to the repo, pushes to GitHub, runspnpm build, and rsyncs the Astro output into the vhost root. No database, no API layer, no cold starts — just static files.
Why a single model, and why 32B
The interesting choice here is not using a frontier model. Qwen3 32B is small enough to run locally, big enough to reason through a structured prompt without going off the rails, and crucially, reproducible from the infrastructure. I know exactly what GPU it's running on, what quantisation, what inference engine. There's no API rate limit, no silent model upgrade, no per-token billing, no dependency on a vendor's terms.
That matters because the point of WillWin isn't to produce the best possible forecast. It's to produce a forecast that's fully reproducible from public inputs with a model anyone can point to and say: "this one, this weight file, this prompt, this data." When a prediction moves, I can tell you which source changed.
What it costs to run
Exactly one API key: Brave Search (BSA tier, ~$5/month), shared across three unrelated projects. The 5090 is already running for other things. The VPS is the same $6/month DigitalOcean droplet that hosts everything else. Total additional monthly cost: effectively zero. No ad revenue, no subscription revenue, no revenue at all — the site is a hobby.
This is the part I keep coming back to in every overdigital.ai writeup — the economics of running real-ish AI experiments on one consumer GPU and a small box are genuinely excellent, and they keep getting better.
What it gets wrong
A lot. The current World Cup snapshot has Spain and France at the top, but either team could be wrecked by an injury tomorrow and the model would only notice to the extent that Wikipedia and Brave News write about it within 24 hours. It has no access to betting markets, which are the actual best single predictor of sporting outcomes. It doesn't know about weather, grudge matches, or the fact that France played 120 minutes three days before their next fixture.
The confidence value on each forecast is capped at 0.92 for exactly this reason — there's always a ceiling on how sure a model reading public text can be about an event that hasn't happened yet. The site says so, repeatedly, in plain English, on every page. Treat the numbers as an illustration of what the pipeline does, not as a signal to act on.
Legal & ethical guardrails
- Data. All input data is public and non-personal. No scraping of paywalled sources, no bypassing of access controls, no personal data collection.
- Not betting advice. WillWin is not regulated as a gambling-related service and does not accept, facilitate, or recommend wagers of any kind. If you are in a jurisdiction where sports-betting content is restricted, nothing on WillWin is targeted at you.
- Trademarks. FIFA, Eurovision Song Contest, Formula 1, Tour de France, the Academy Awards, and all team/driver/artist/film/studio names are the property of their respective owners. WillWin is unaffiliated. Their names appear purely as reference descriptors for the publicly known contestants in each event.
- Privacy. The site uses anonymous Google Analytics (IP-anonymised, cookie-consent gated) and collects nothing else about visitors. See the privacy policy linked in the footer.
- No liability. Use of WillWin is entirely at your own risk. The site and this article are provided on an "as is" basis with no warranties of any kind, express or implied.
Future directions
The architecture generalises. Anything that has (a) public structured data, (b) a Wikipedia page per contender, and (c) a news cycle on Brave would slot into the same pipeline in a few hours of work. Election forecasts would be the obvious next domain — but also the one I won't add, because the stakes of a badly-calibrated AI model publishing election probabilities are a different category of problem entirely.
The other obvious direction is backtesting. The append-only history.json file per event means that, after each event resolves, every nightly forecast can be scored against the actual outcome and a calibration chart published. That's the real payoff of the experiment — not "did the model pick the winner," but "when the model said 23% confidence, did the event happen 23% of the time?"
Until then, it's a nightly exercise in how far one open-weights model and a stack of public text can get before the season starts.
Live at willwin.ai. Press D on any event page to see the full data history. Remember: technical experiment, not a prediction service, not betting advice.


Discussion
Be the first to comment