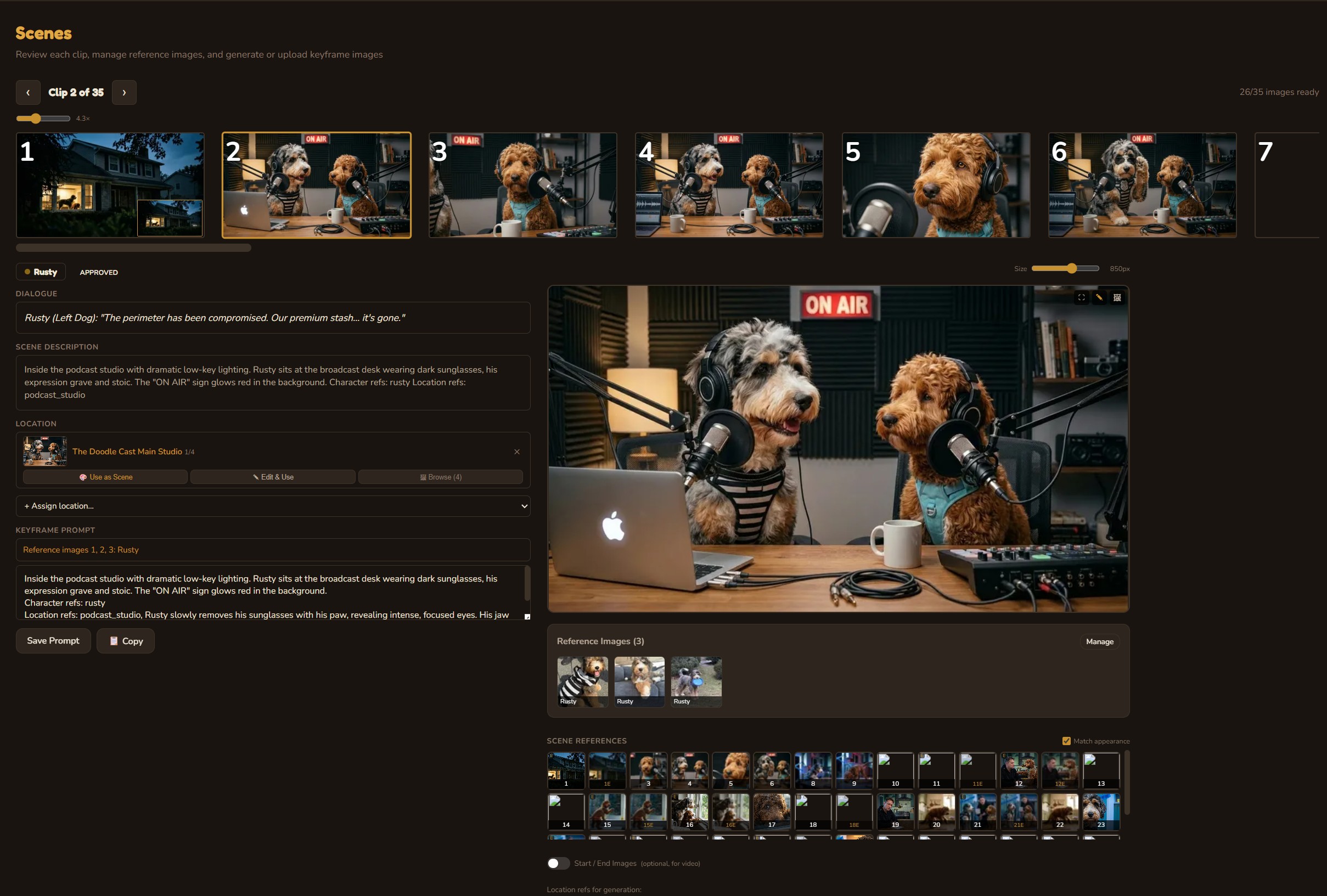
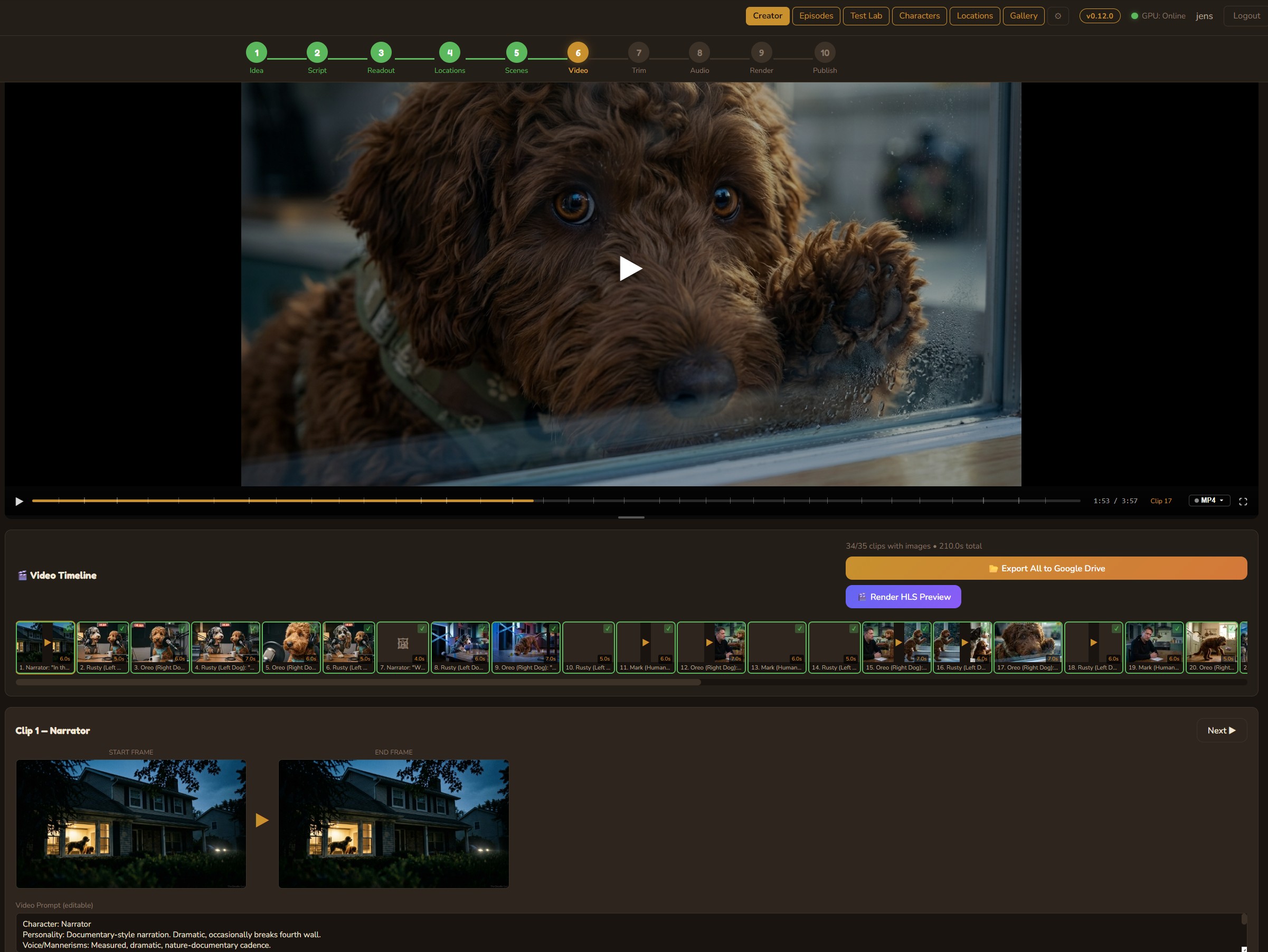
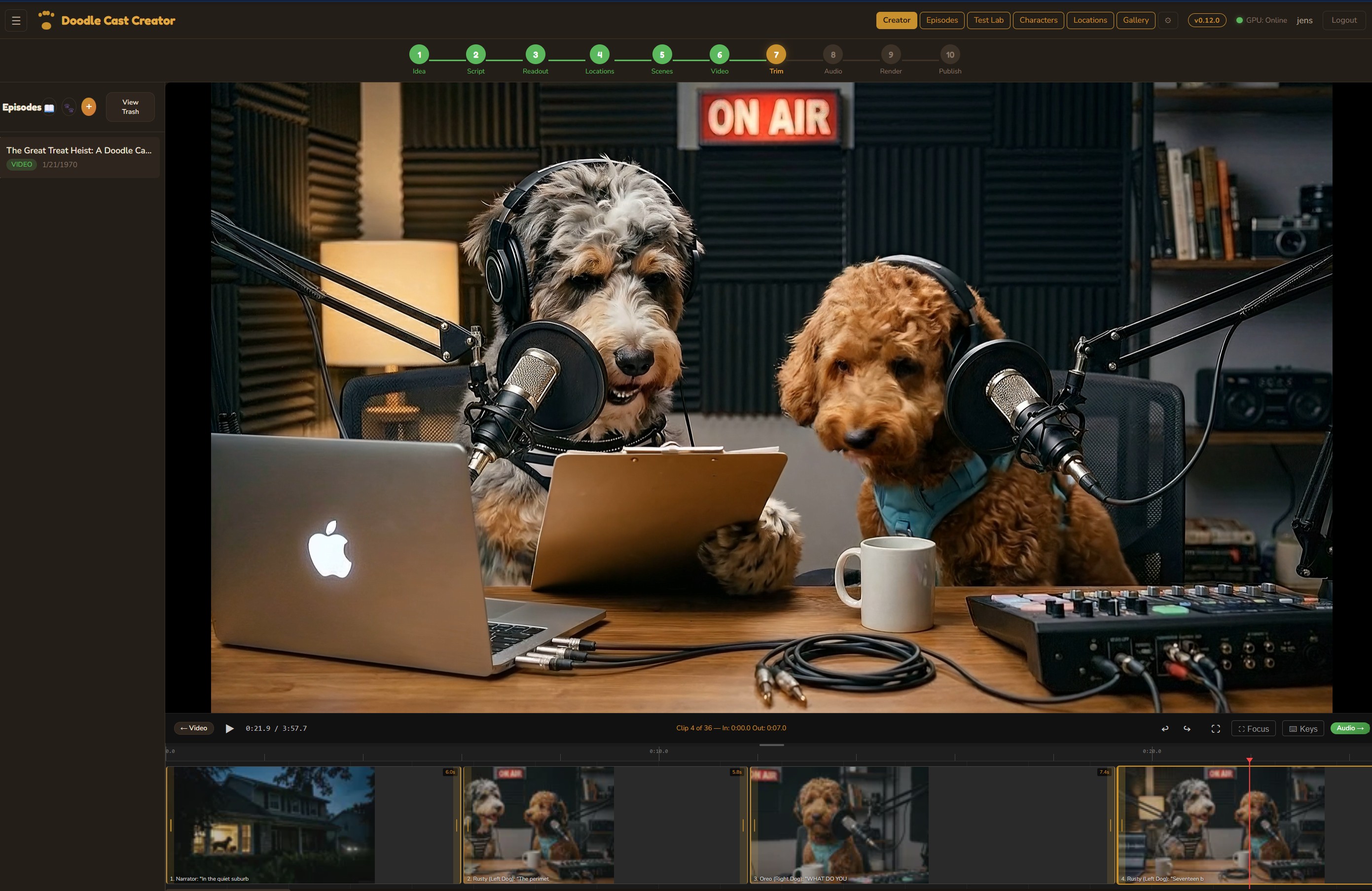
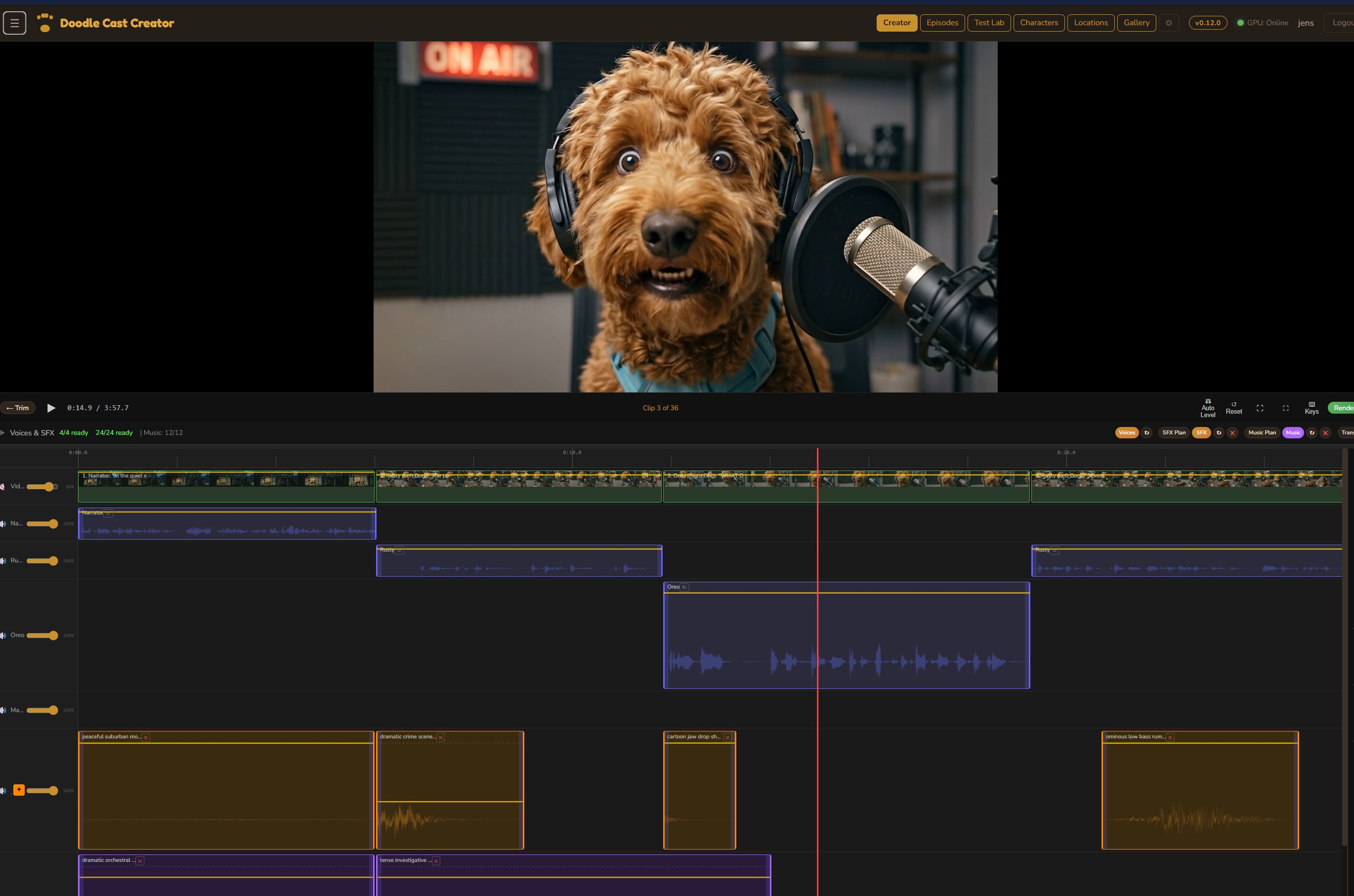
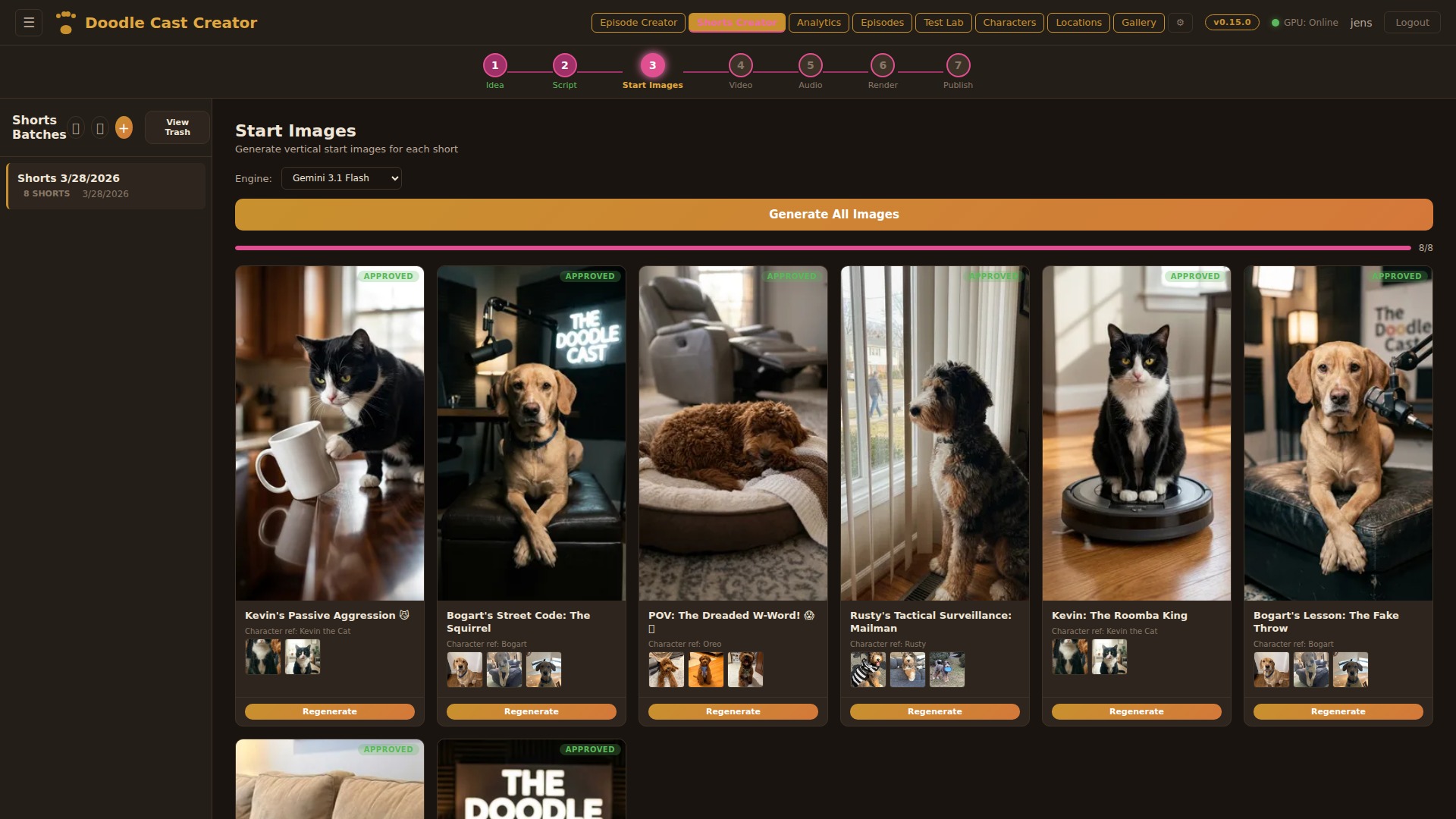
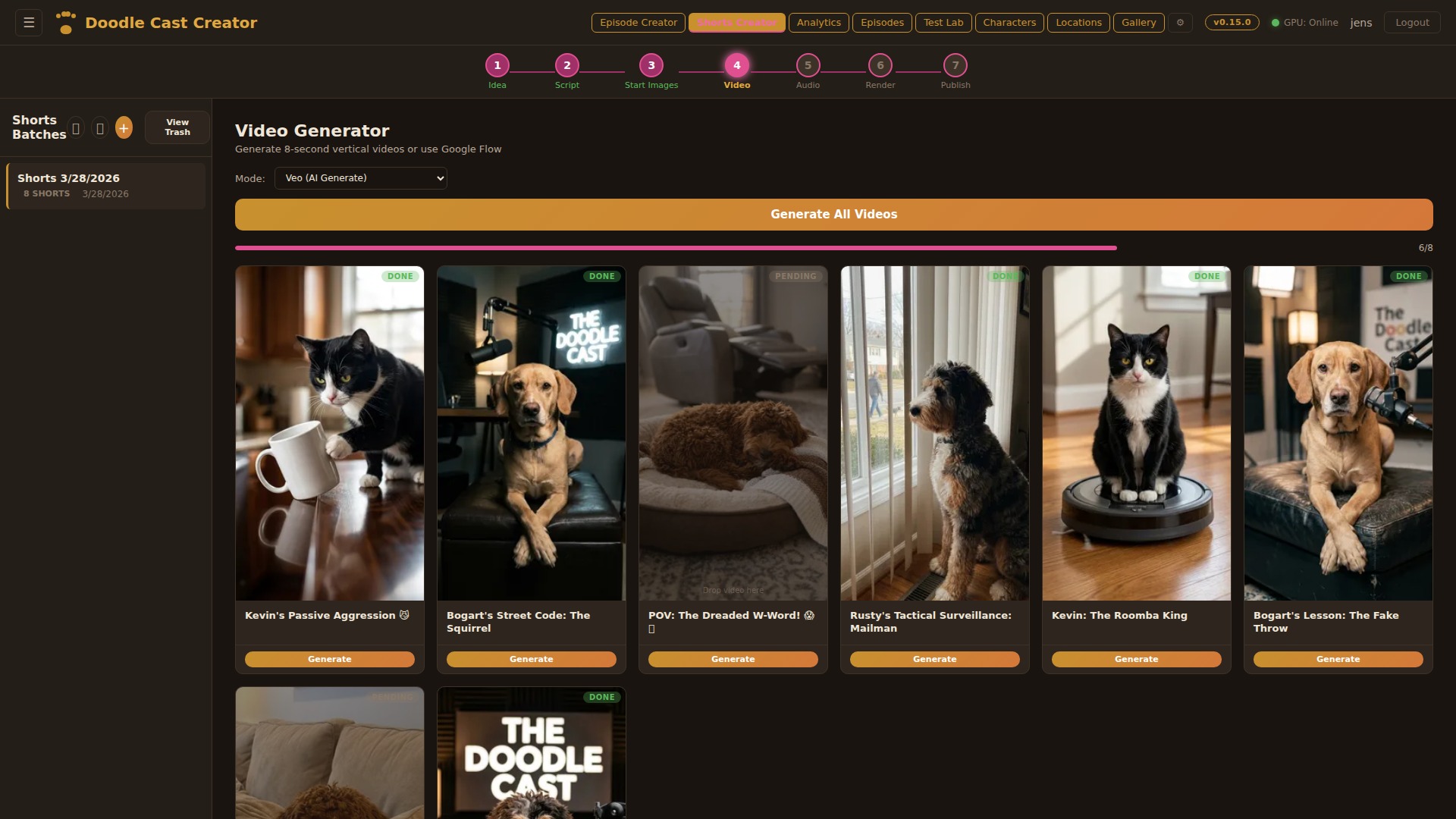
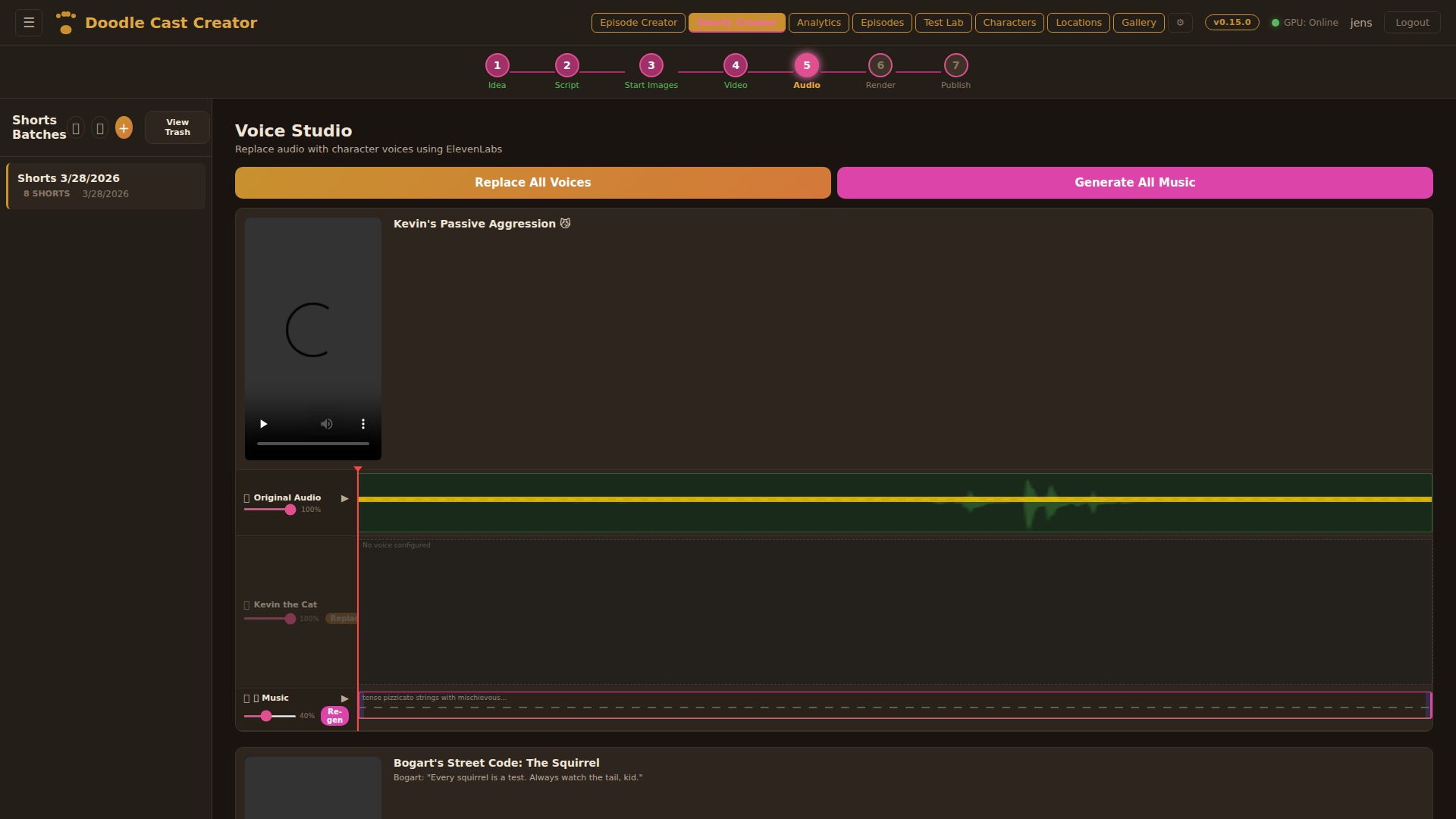
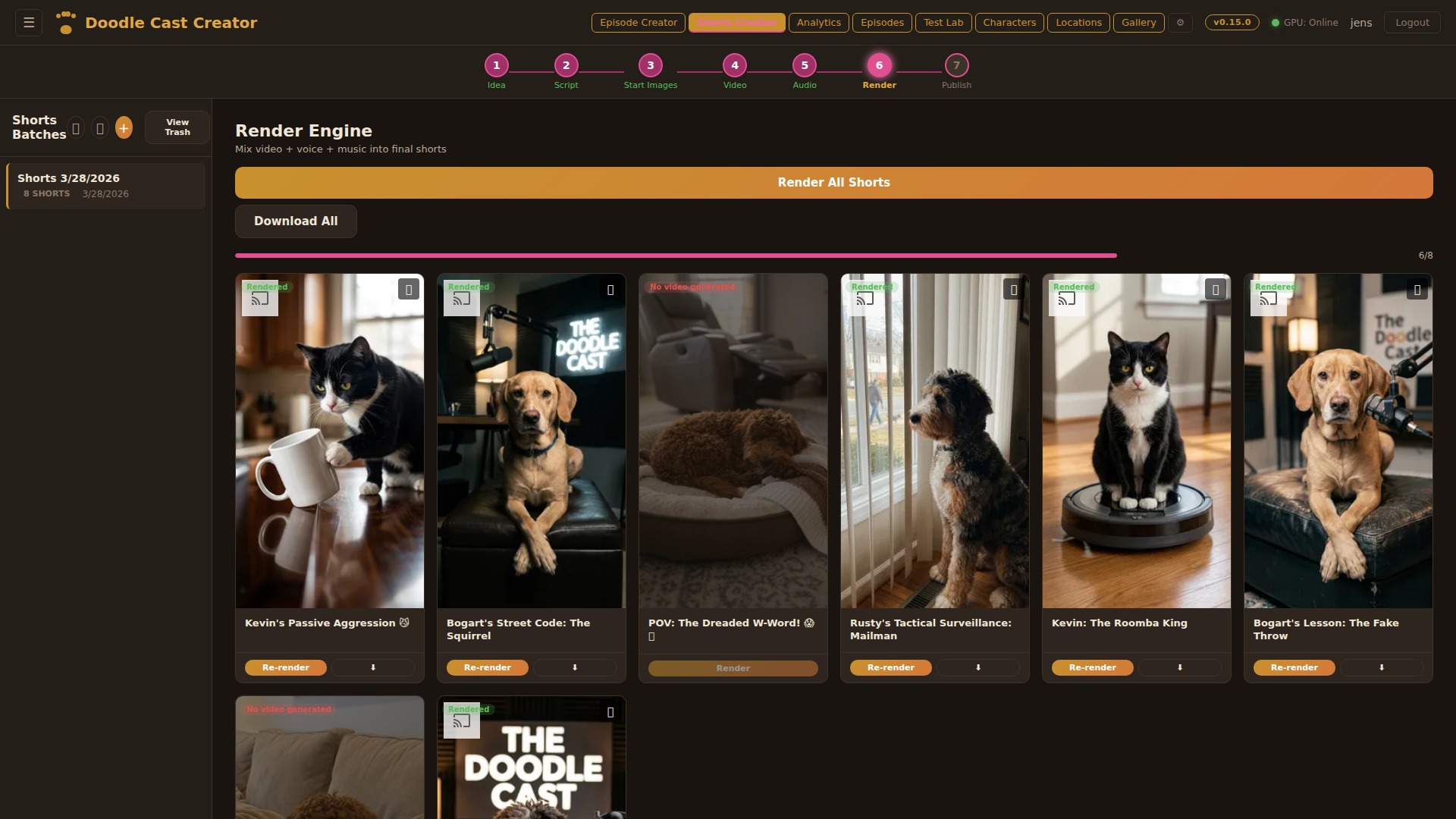
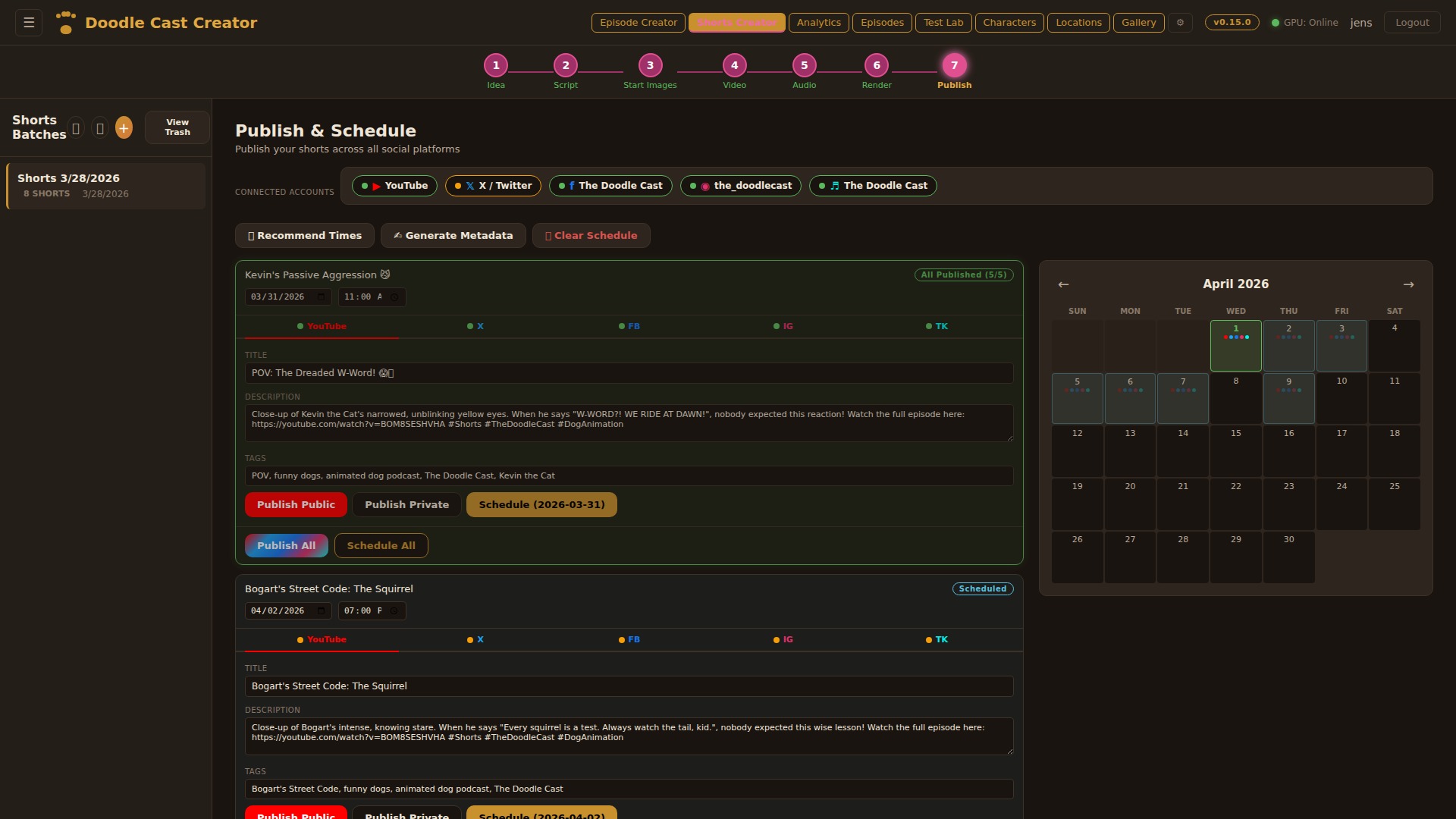
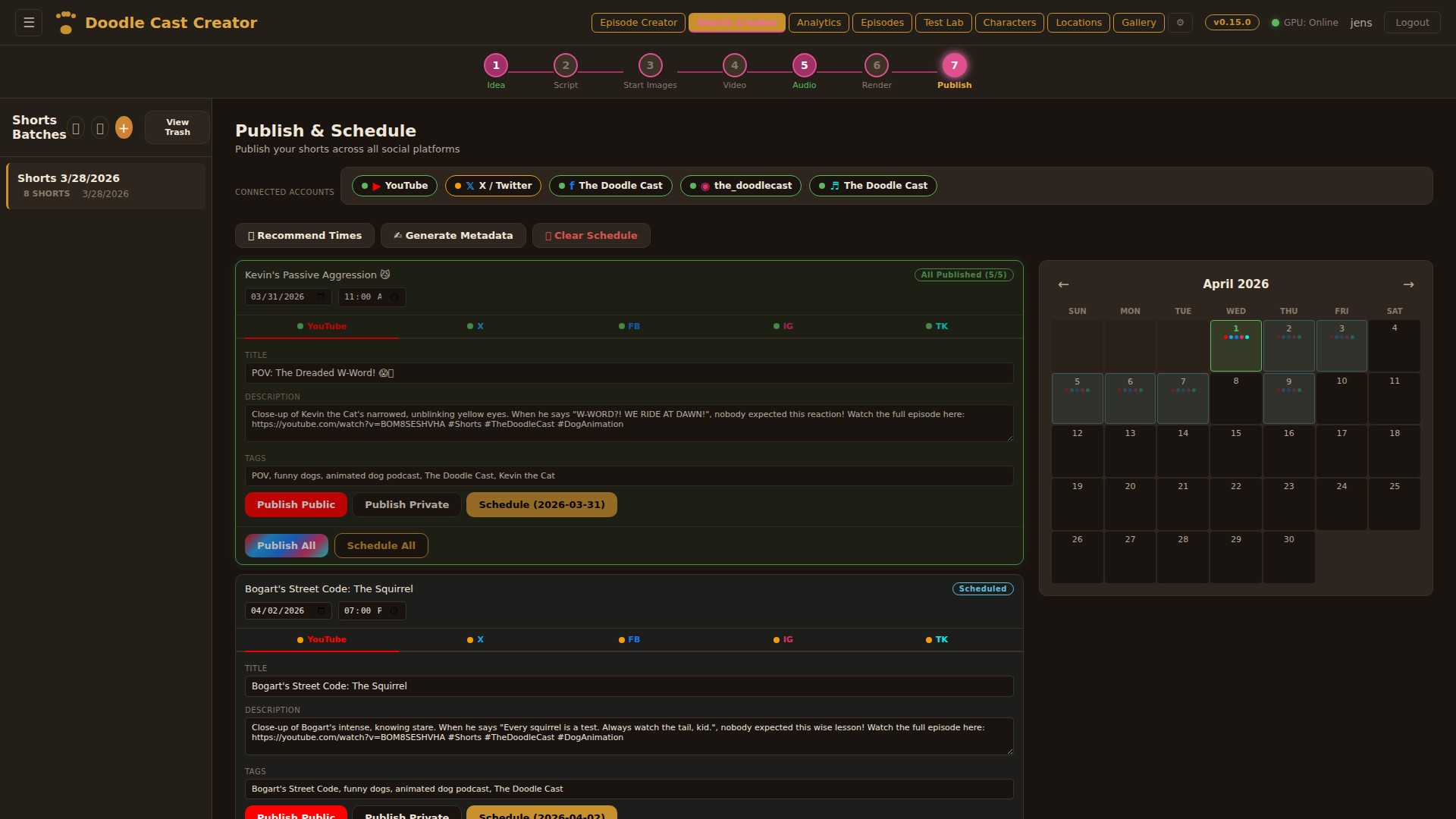
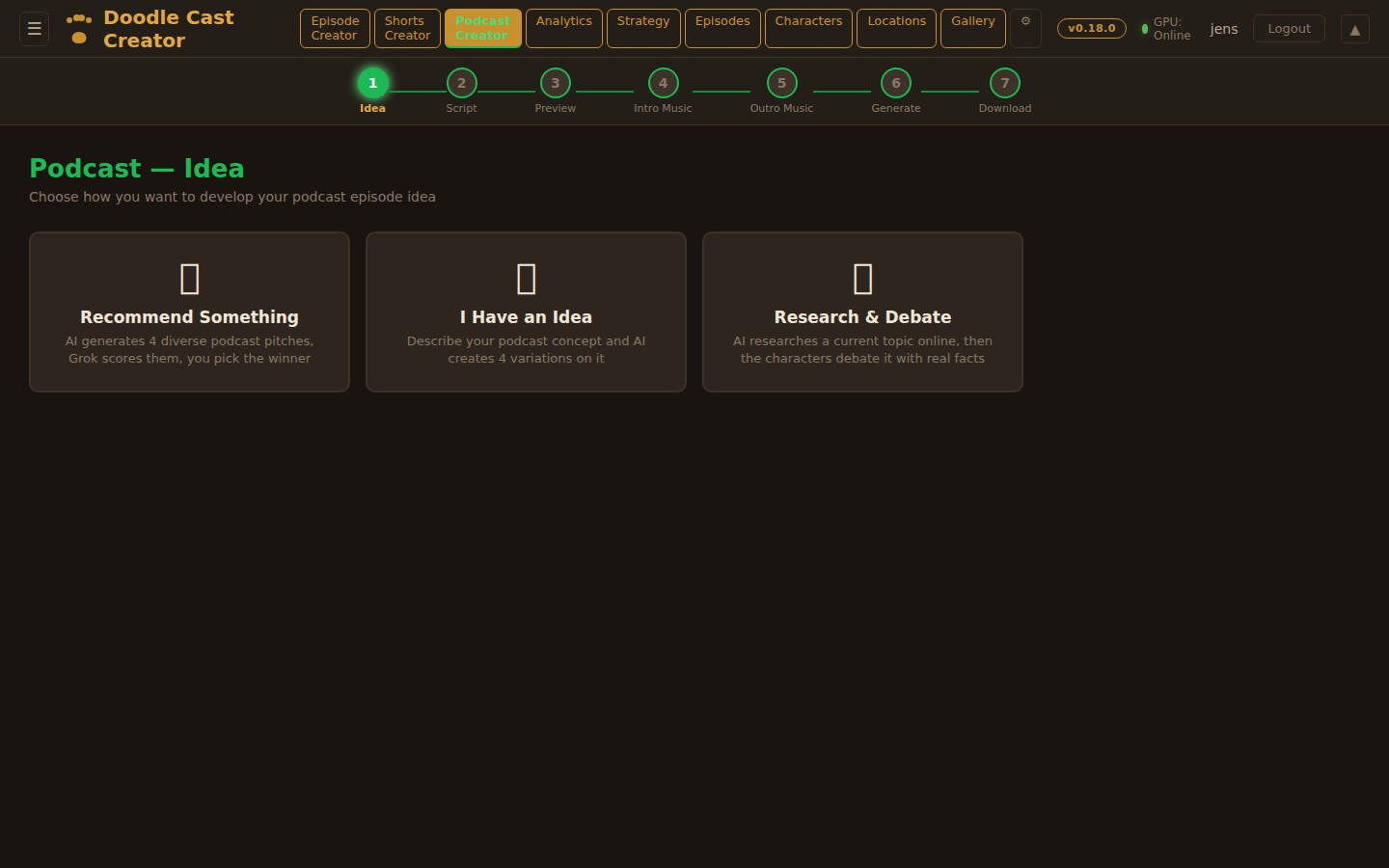
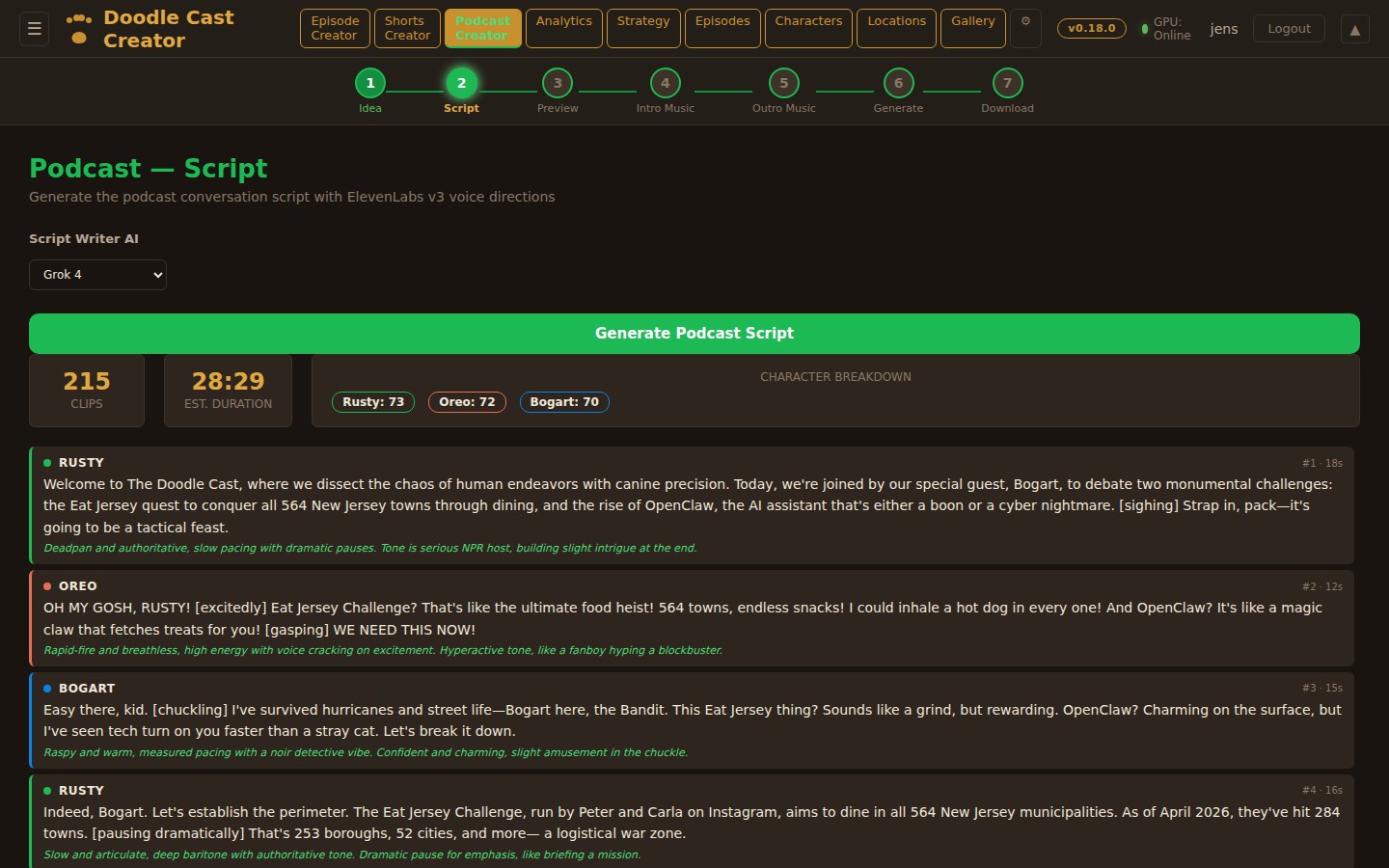
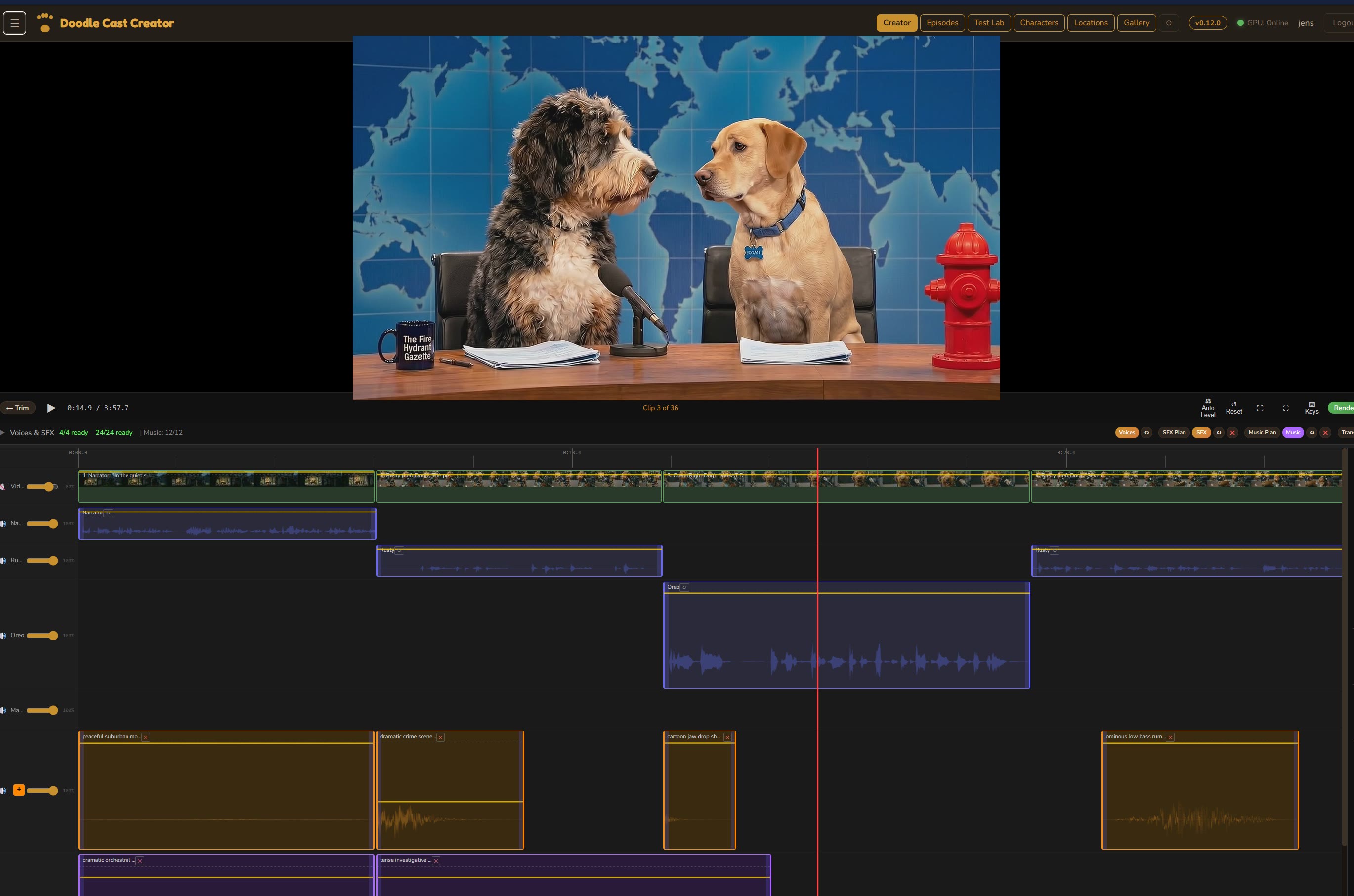
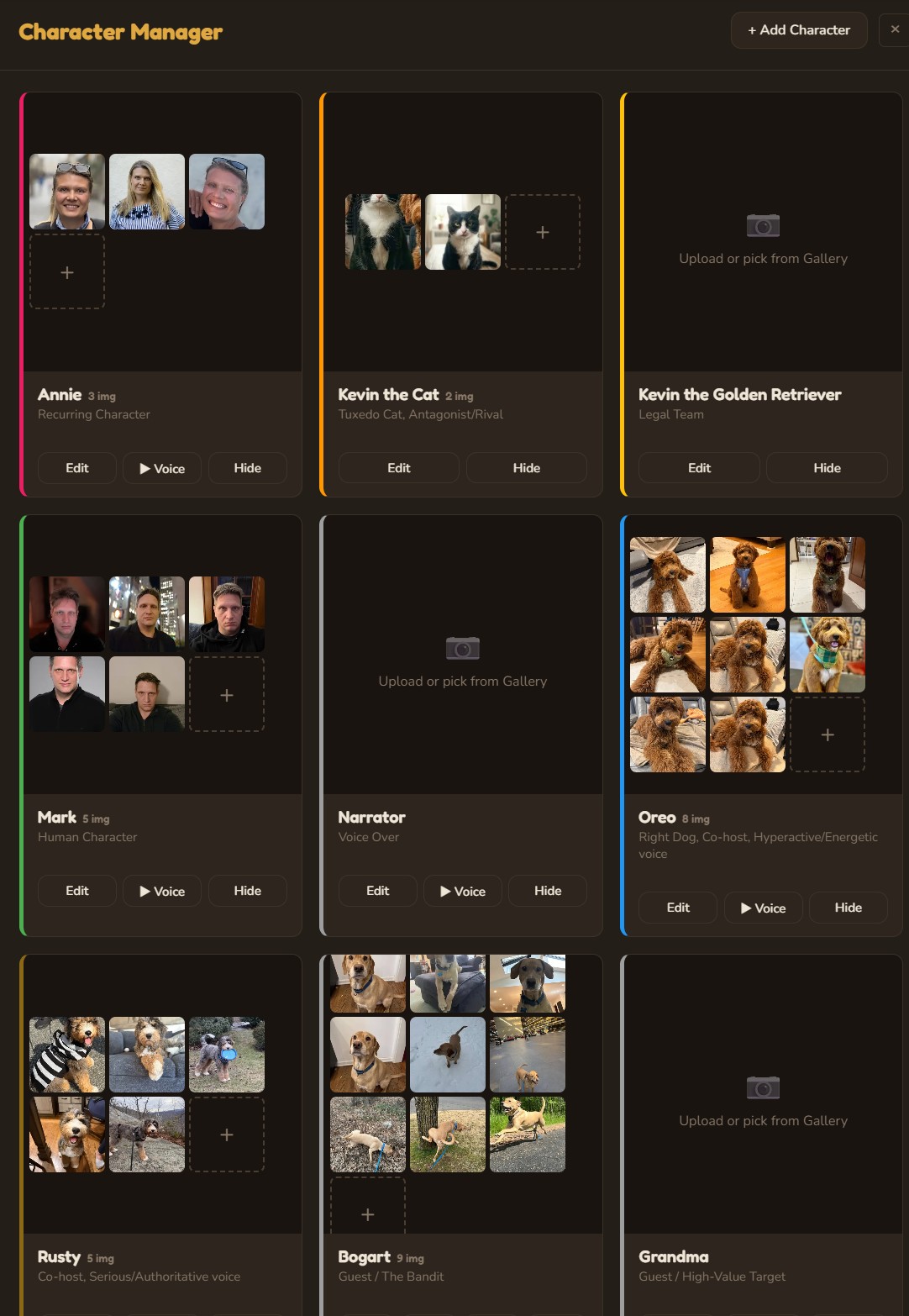
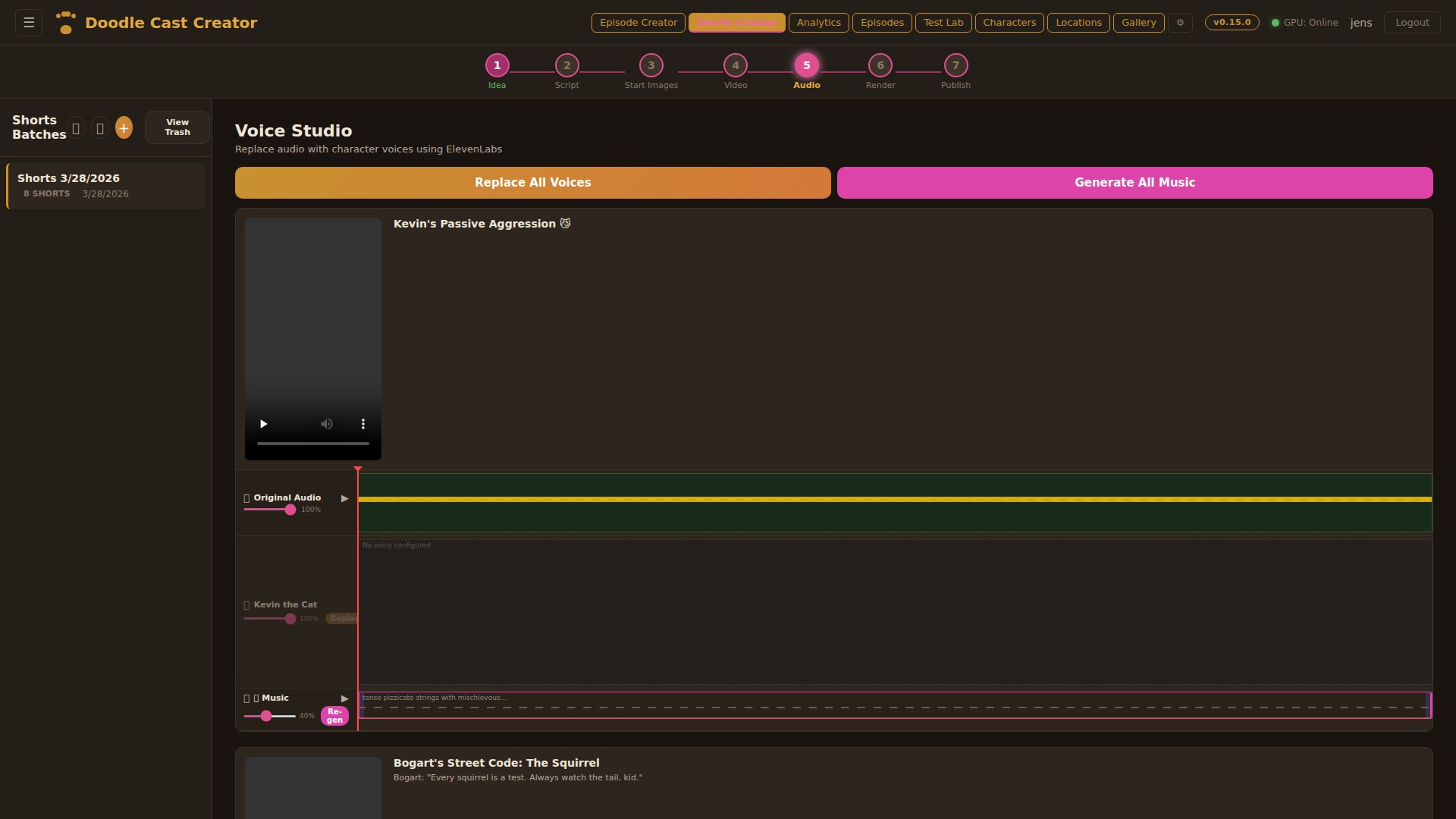
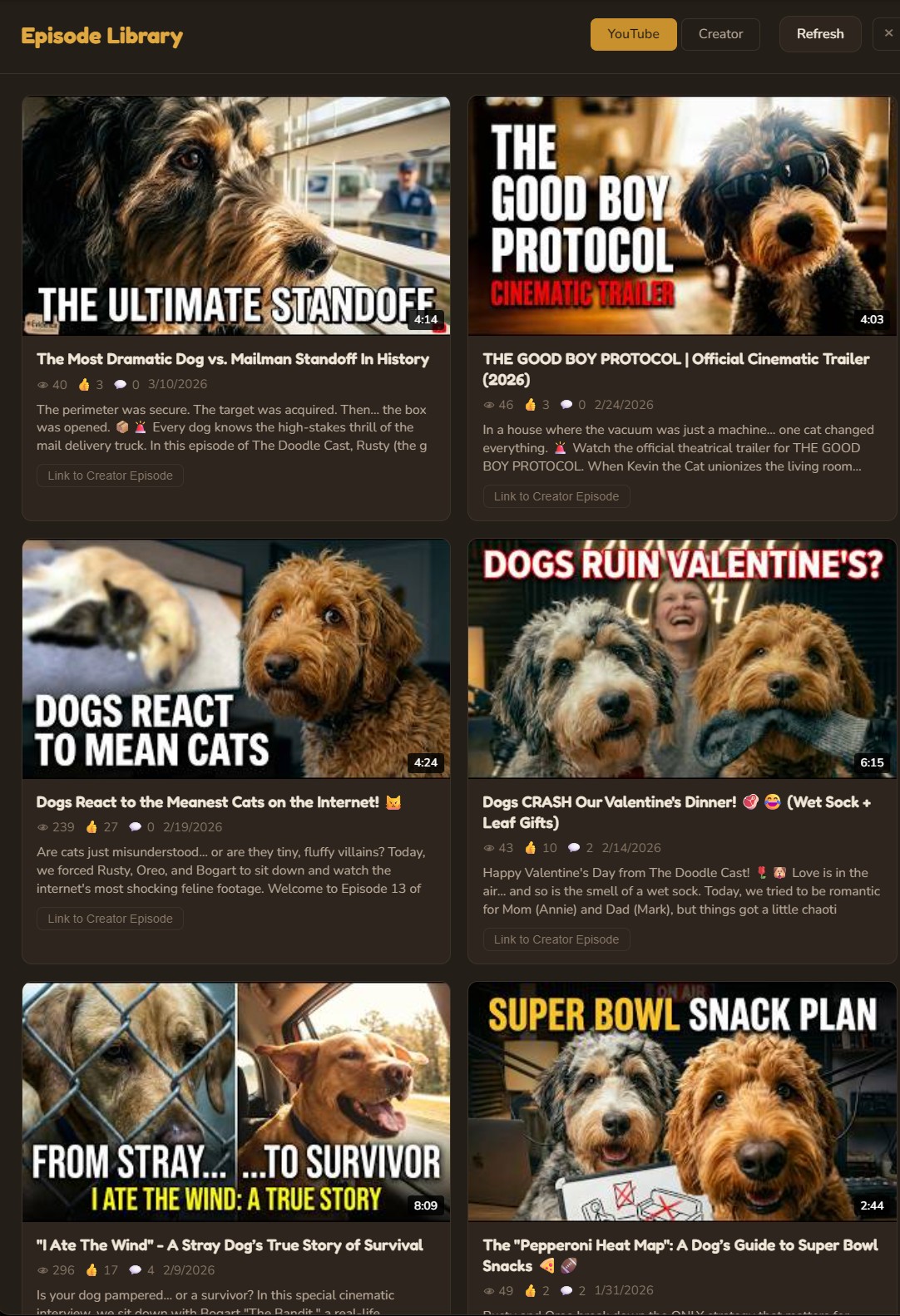
Step 01
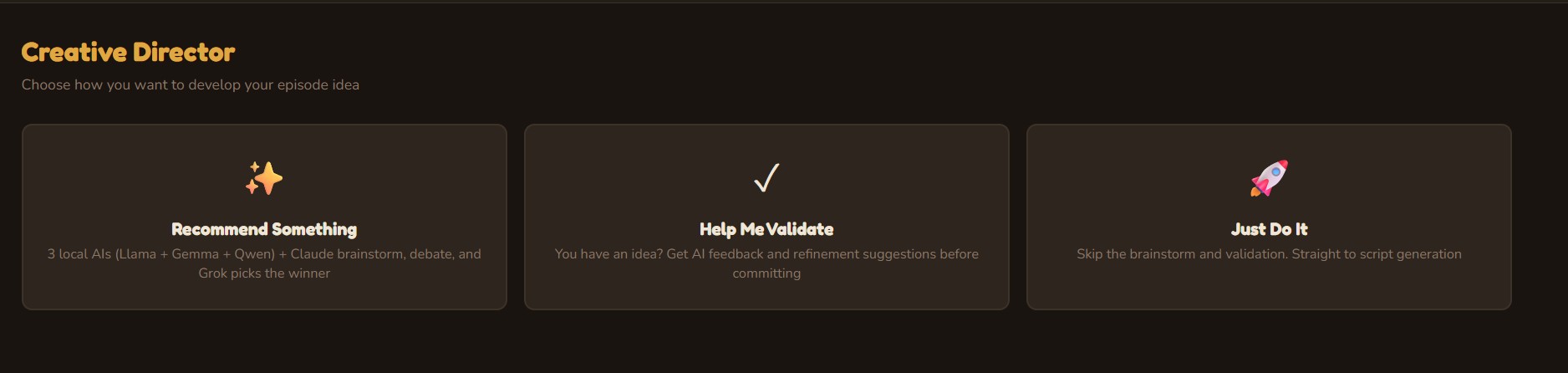
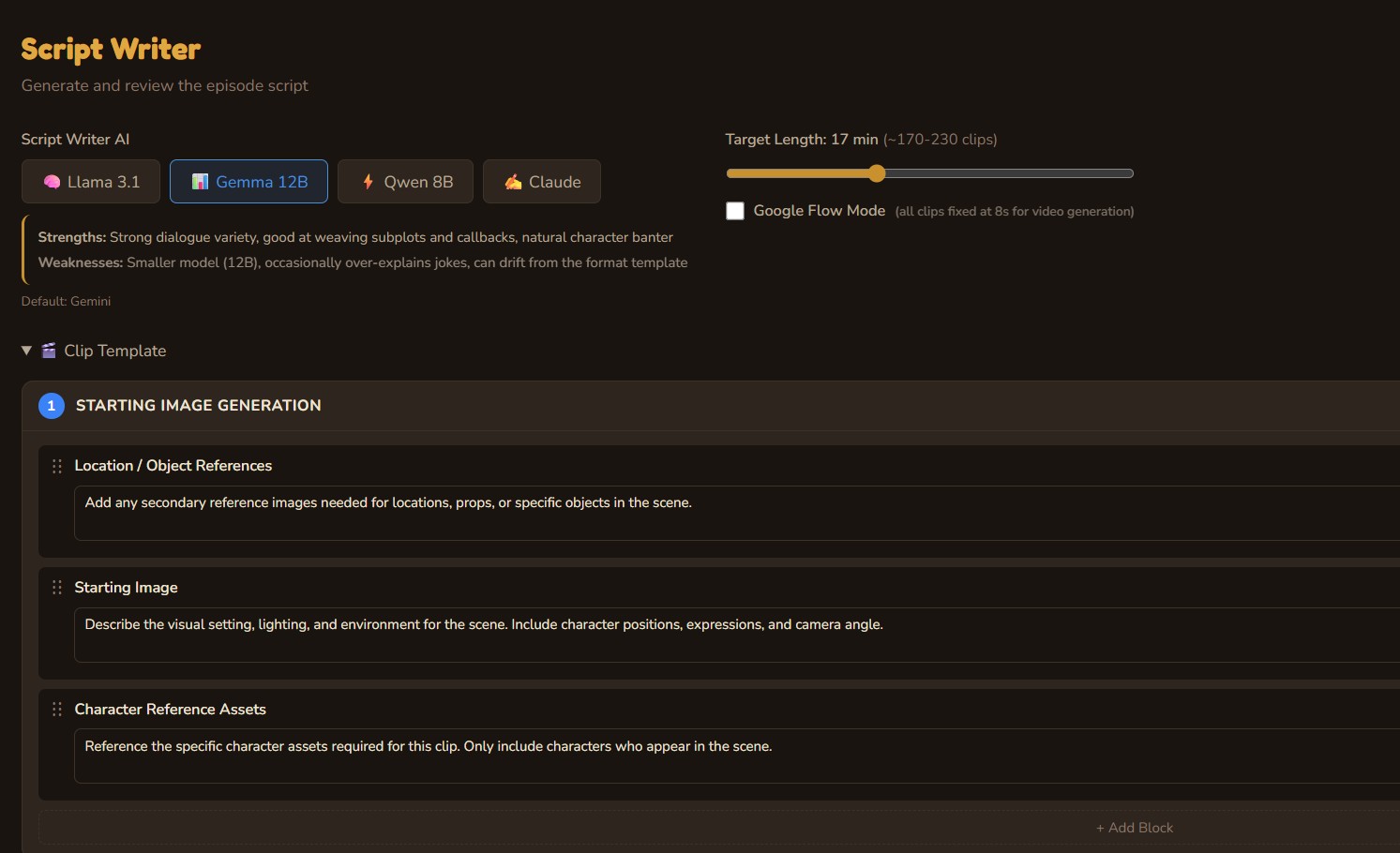
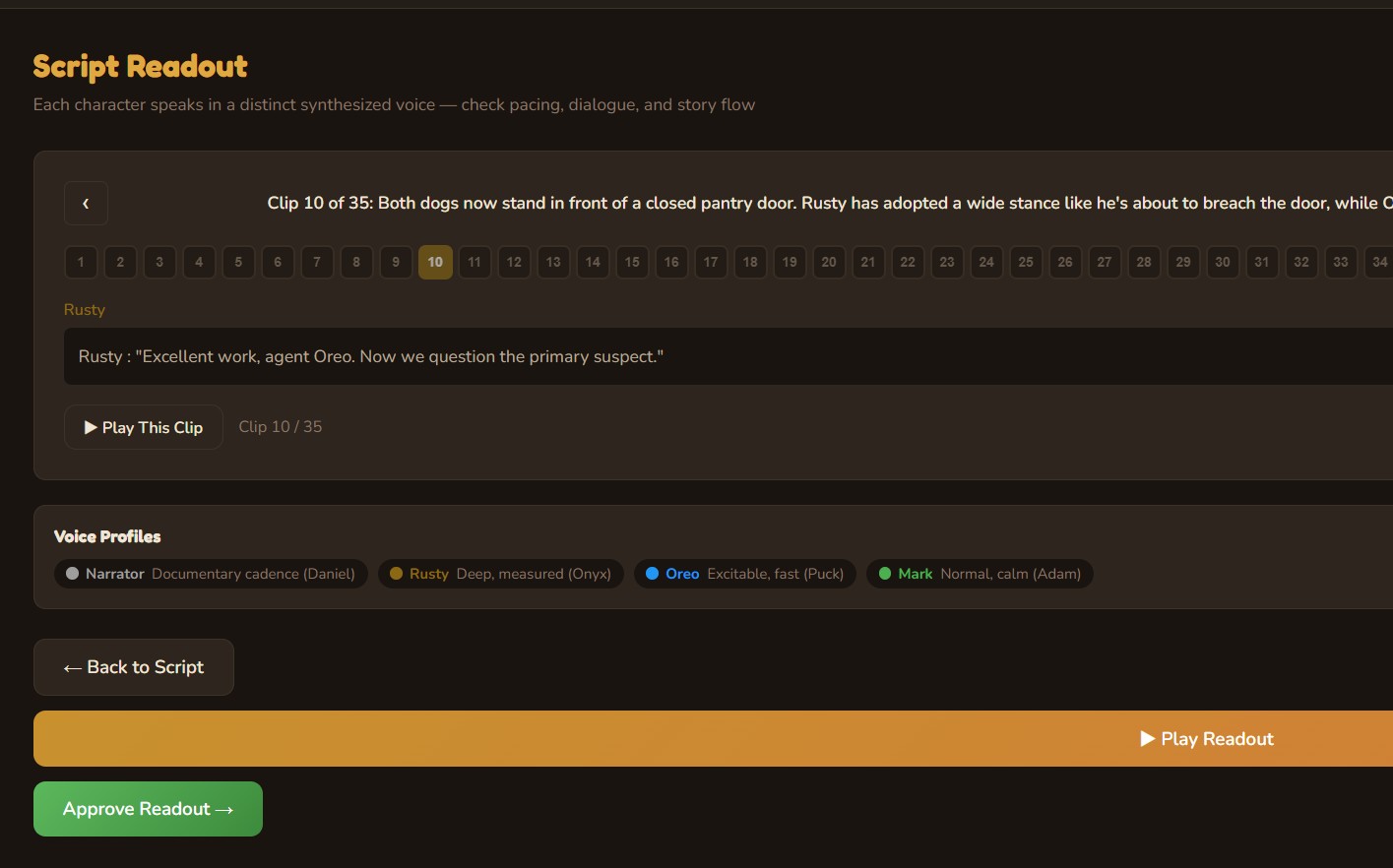
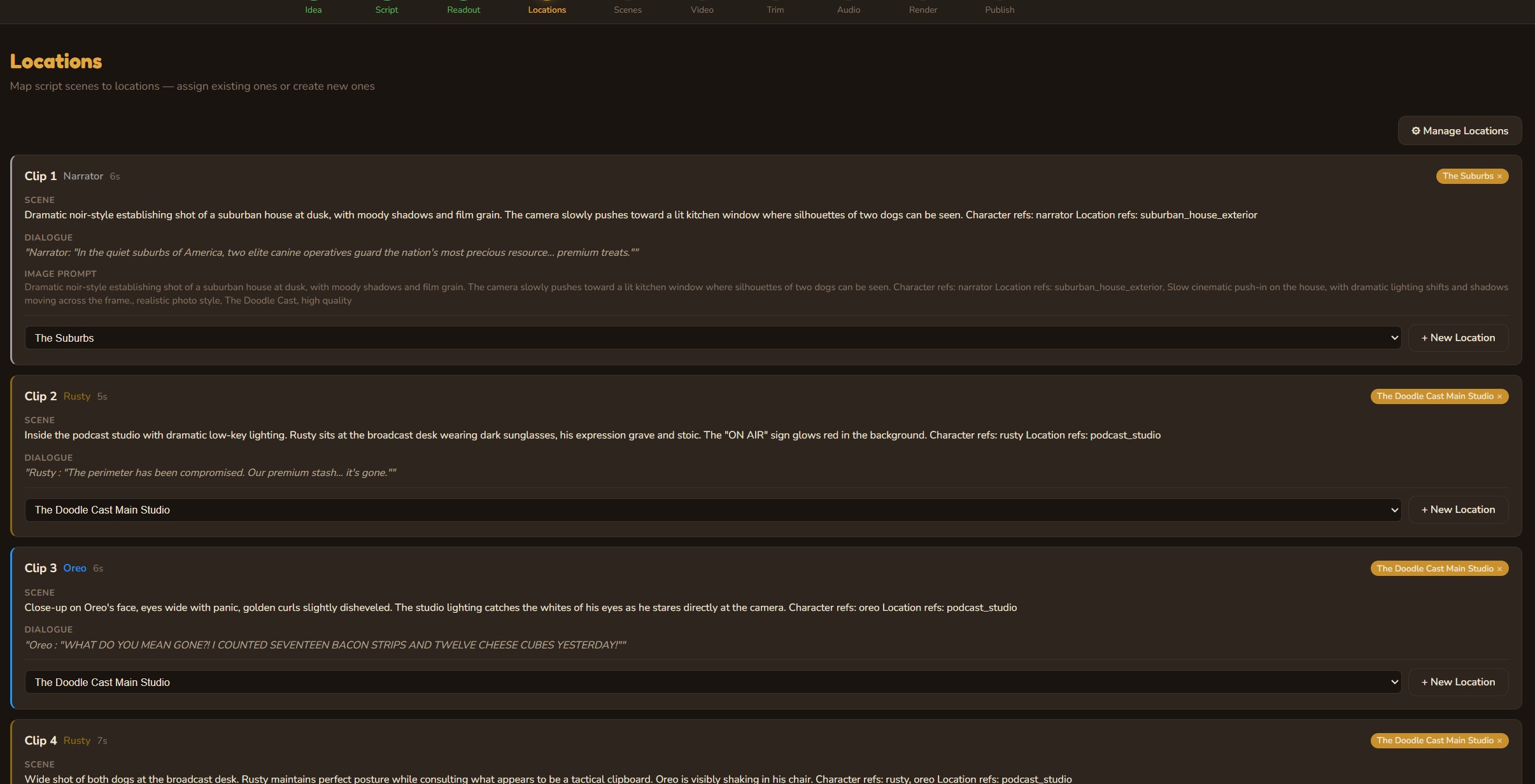
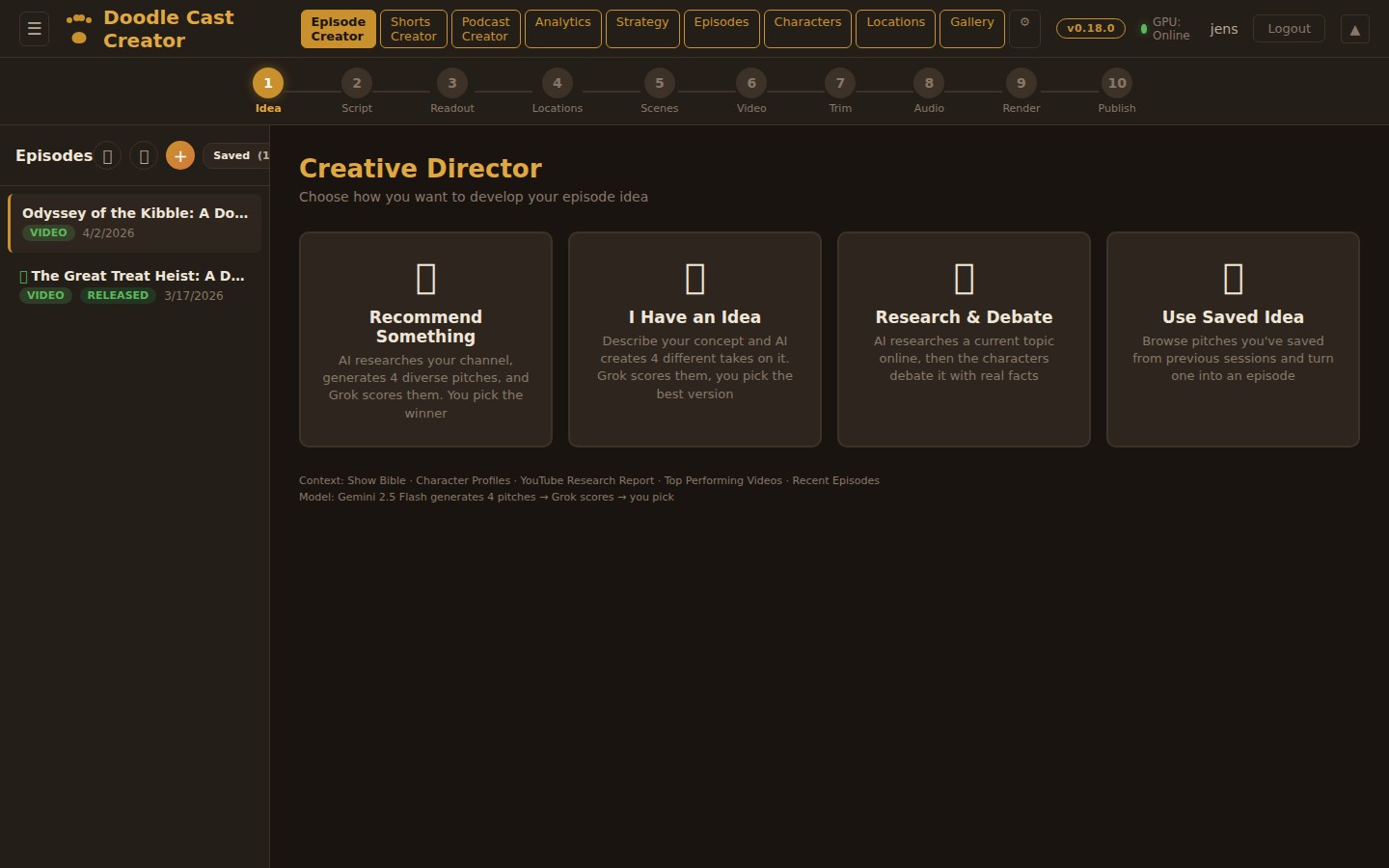
Creative Director
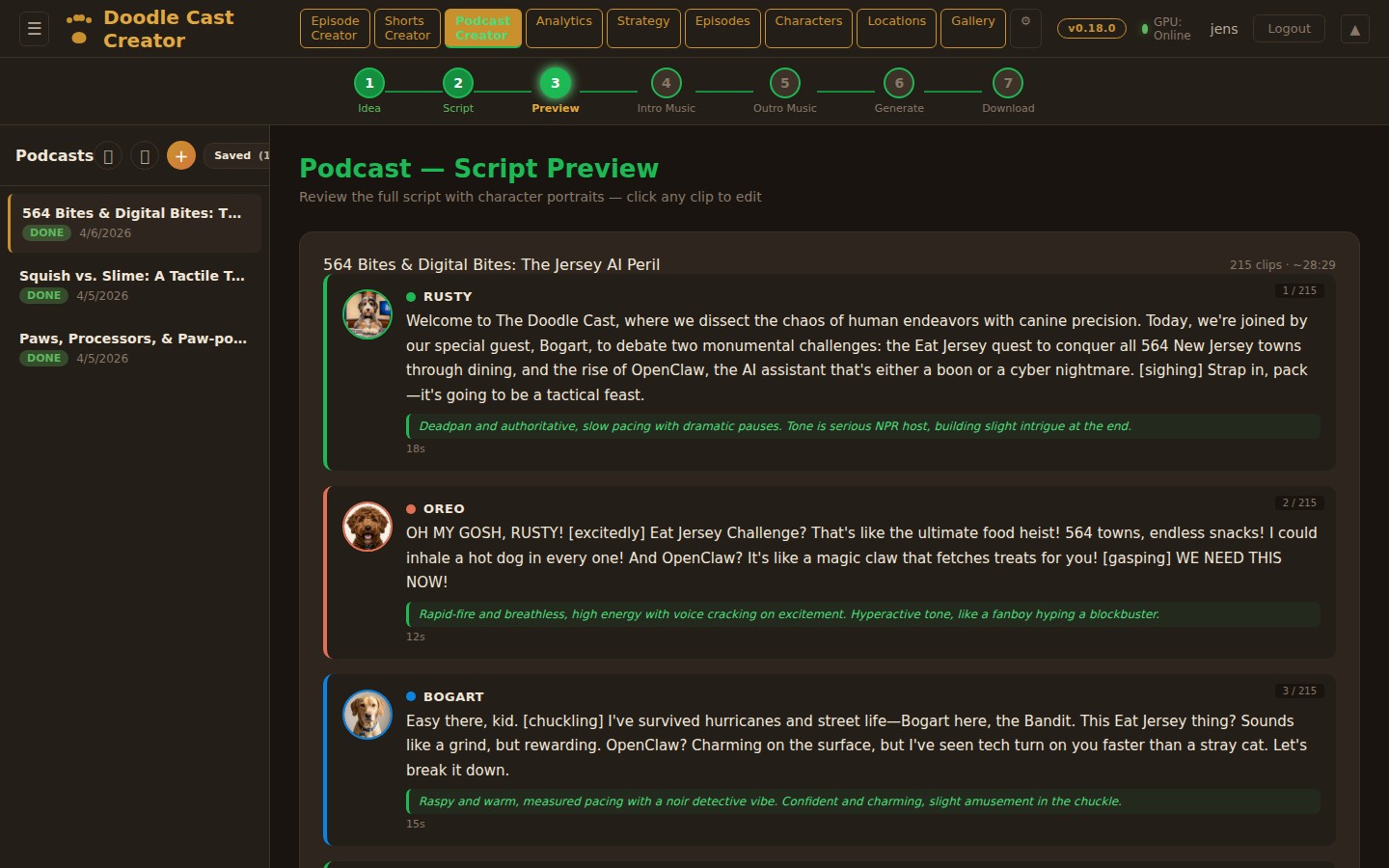
Three AI personas independently pitch episode concepts, then debate their merits. A judge model evaluates each pitch with live web search for topical relevance and picks a winner — or you bring your own idea and let the panel pressure-test it.